本人对 Stable Diffusion 的全部探索
随着10月7日的 NovelAI 模型“泄漏”事件,利用SD生成图片便开始大火。咱作为一穷学生,手头唯一有过的显卡,还是亮机用的 ATI HD 4600,因此只能去借用云GPU资源了。
下面会给出一些SD相关的资源,教你如何在云上跑,以及个人生成的可供欣赏的图片。(大概会持续更新)
关于本地搭建,由于咱没有实际操作过,所说的一切都是纸上谈兵,所以还是丢几个教程罢。
部署时请注意网络环境,“系统代理”可能不起作用,请自行更改为 TUN隧道 (虚拟网卡/VPN) 模式,
或搜索“git/pip 代理设置/镜像站设置”。
Model 收集:
若是想借助云GPU,咱在这方面作了不少探究,目前来说有这么几种方式:
(配套的GitHub仓库,配合食用)
1. Google Colab (需架梯,优先考虑)
Google 大气!直接免费给 Tesla T4,应该是能免费拿到的最好的 GPU 了。缺点是内存略少,配额也略少。
它的分配大概是按GPU用量计算,间断生成每天大概能跑 1.5-2h,配额用尽自动停机。(戏称 AI 防沉迷)
需要注意的是,该方案要求有稳定的互联网连接,否则断线后可能会需要重新配置环境,浪费配额。
推荐 notebook:Fast SD
由于 Colab 内存限制,请配合较小的模型使用,这里建议转存 animefull-final-pruned.
在“Model Download/Load”模块填入分享链接或转存后的路径,然后依次运行所有单元格即可。
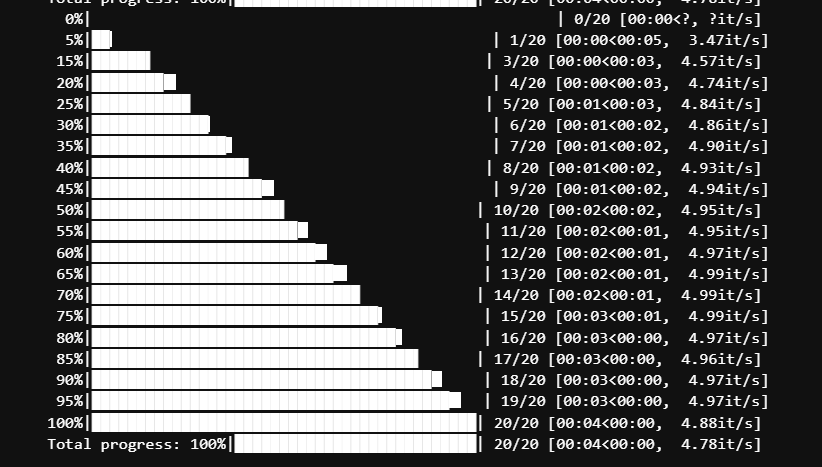
备选:中文版 NovelAI官方前端、by Altryne、SD Voldemort下图为基准测试,即 t2i 默认配置下的生成速度,点击查看。(仅供参考,实际不是很稳)
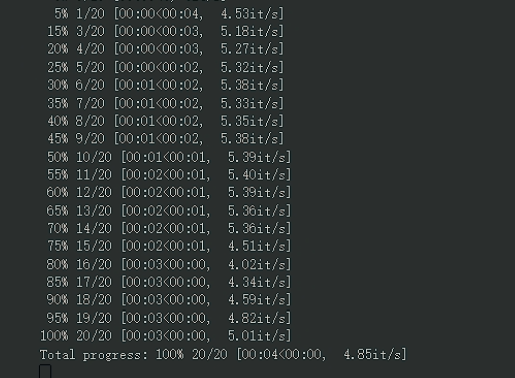
2. Paperspace (稳定免费 6h)
这家提供的是 Quadro M4000,性能不强,不过内存倒是给够了。
实行先到先得机制,可能会有免费机子耗尽的情况,目前来说只要多次刷新就能刷出可用机子,抢到便可完整用6小时。
这家的永久存储空间只给了 5GB,相当于每次运行都要重新下载模型,不过目前来说下载速度可观,影响不大。
官方引导 (En):SD Paperspace
注册时需要手机号。
创建项目时若没有免费的机子,可以刷新一下,或换个时间。
notebook 中第一个单元格需要手动去掉 2-5 行注释。下载模型推荐“animefull-final-pruned”,可选下载 Hypernetworks 部分。其余请根据说明运行,祝成功。下图为基准测试,点击查看,注意单位为较慢的“s/it”。
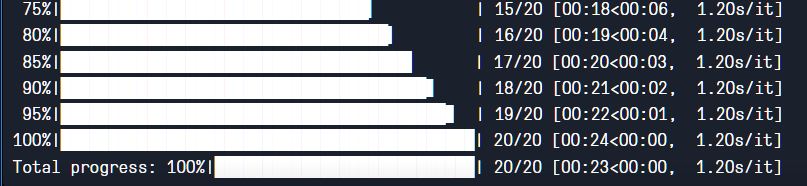
3. Kaggle (一周至少免费 30h)
这家提供了 Tesla P100-PCIE,性能中上。虽然内存也不是很多,但这里内存占满不会像 Colab 一样强退进程,而是会缓慢持续运行。加上免费时间充足,存储空间也给不少,所以值得一试~
今天突然发现它有提供 Tesla T4 x2,虽然目前只能用到一个,但 T4 就很香了好吧。基准测试见后。
推荐 notebook:StableDiffusionUI
先注册账号,然后进入上面的网址,选择右上角Copy & Edit,更改右侧“Settings”中的ACCELERATOR为 GPU,
PERSISTENCE为 Files only,并打开Internet on选项。
若无法切换到 GPU,请先前往右侧下方提示处验证手机号。
首次需执行除最后外的所有单元格,往后一般只需执行倒数第二个单元格即可。
开启底部“Console”,便于查看日志输出。下图为基准测试,点击查看。(先 T4 x2,后 P100)
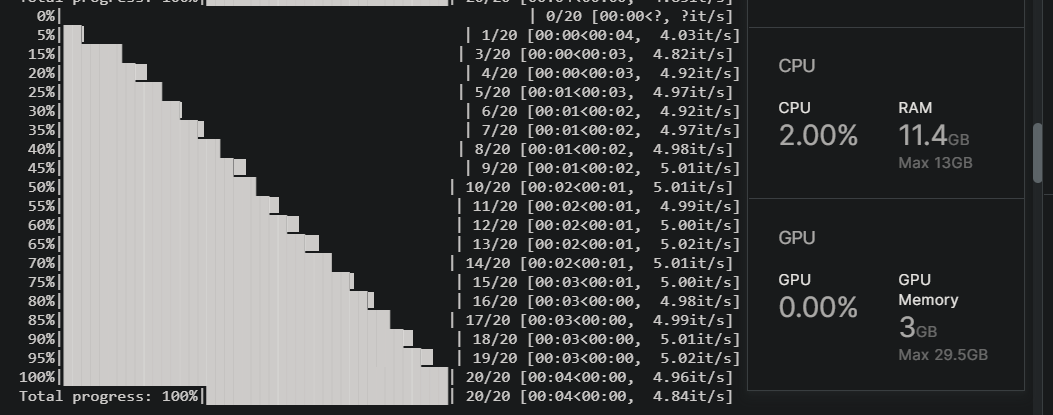
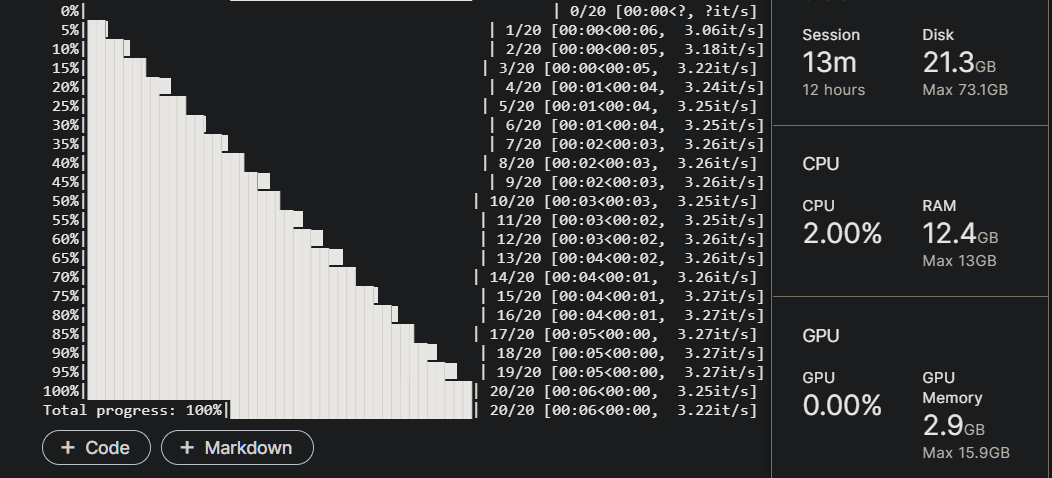
4. Amazon SageMaker Studio Lab (免费稳定 4h)
这家给的也是 Tesla T4,4核 CPU,16G 内存,15GB 存储空间。
配额是连续可用 4h,24h 内可用 8h。
注册账号无法立刻拿到,需要排几天的队等待审核。
存在各种问题,暂时无法用于生产。请等待后续探究。
问题主要在于不给 root 权限,加上 gradio 无法连接,好在都能解决。
自制 notebook:
启动前记得将“Compute type”改为 GPU。
首次需运行除最后外的所有单元格,往后一般只需运行倒数第二个单元格。
存在无法正常运行的可能,如果无法独立解决,请考虑其他平台。下图基准测试,点击查看。
以下为国内平台。使用时请注意不要生成违反国内法律法规的图片。
5. 飞浆 AI Studio (免费资源充足)
这家为百度旗下,每周提供 48h 的 Tesla V100 (每天 8-16h),或者 4h 的 Tesla A100,加上 100GB 永久存储。
应该说很不错了,慷慨到令人意外。
由于使用 ipfs 网关下载模型,速度不是很快,
已经将模型重新上传到国内网盘了,但仍然较慢,建议用免费的 CPU 环境来等待下载。
国内网络环境实在无法支撑环境搭建,另作考虑。
最后说几点注意事项:
--share带的 Gradio 服务,似乎存在断连问题,即webui假死之类,需要刷新重新配置才可。不论有无代理都如此;(更新 webui 后可用 ngrok 替代,亲测体验不错)- 根据实际资源使用情况,合理添加
--medvram、--lowvram、--lowram; --share请务必搭配--gradio-auth [username]:[password]使用;- 纯 CPU 需添加的参数已从
--skip-torch-cuda-test --no-half --precision full简化为--use-cpu; - 若出现
Torch is not able to use GPU相关报错,请先尝试更新 PyTorch;
ngrok 使用指南:
- 注册/登录 ngrok 后,前往授权页可获得 Authtoken;
- 需添加参数
--ngrok [Authtoken],可选参数--ngrok-region [region],具体请参考文档,默认为 us; - 使用时请去掉
--share参数,但不必去掉--gradio-debug; - webui 默认给的是 http,若访问白屏或一直加载中请将网址改为 https;
- webui 会先给出隧道网址,如果找不到可以稍微往上翻翻;
- 只能同时创建一个隧道,否则报错 Access denied;
- 个人感觉 ngrok 更加稳定,也更安全,推荐各位尝试。
附录:Azure ML 体验
如果你有学生身份,那么便可以免费体验包括 Azure 与 DigitalOcean 在内多个云服务商的 IaaS 基础设施。DigitalOcean 我暂时没有涉足,就先说说有关 Azure 的一点经验。
- Azure 学生订阅自带 $100,但是你无法直接去购买带 GPU 的 vps,会提示没有配额。因此考虑转向 Azure ML 平台。
- Azure ML 提供了最高 16核 32G CPU实例,与 6核 56G 带 Tesla K80/M60 GPU实例,性能其实并不算很好,并且所有的资源都是会扣额度的,除了计算实例,存储,网络都会收费。
(当关闭所有实例时,工作区的存储似乎不扣费,免费存储额度暂未知,怀疑 100GB。) - 由于环境不同,写 notebook 不是很容易,还是先试试纯 CPU 下的性能吧。(据说跑满一半核心是正常情况)
基准测试点击查看。
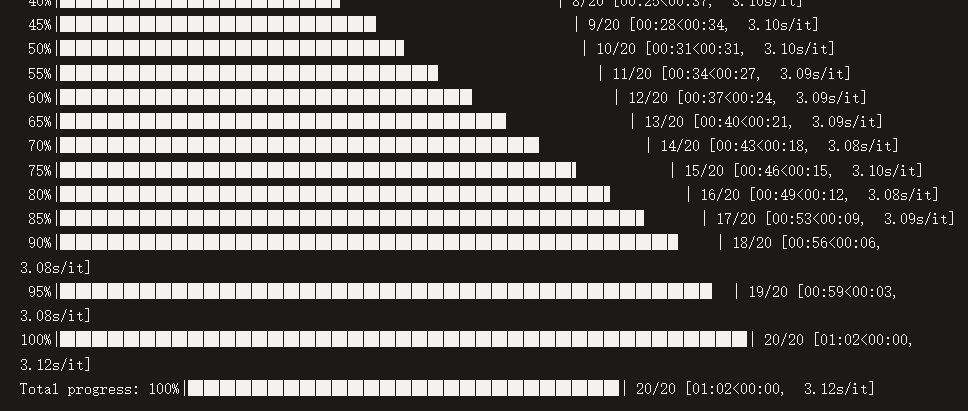

- 上次用 GPU 尝试结果不能出图,之后有时间再试吧。况且按那价格,100刀可能还不够造 100h 的。x
倘若你想尝试搭建,请先在 AzureML 创建好工作区,添加合适的计算实例。然后下载该文件并上传至工作区文件夹,之后按单元格注释操作即可。
完全不保证可用性,并且可能存在扣费行为,风险自担。
说起来,应该没有人是为看图而来的吧。
咱一直在费心于基础设施搭建,哪有空研究咒语啥的,生成的结果只能说堪堪达到“能看”的范畴而已。
唉,AI 对于人体四肢的生成还是不太 Stable 啊,不是数量不对就是空间逻辑不对——
目前认为,欣赏 AI 的作品,还是要重数量而非质量,尽量不要细致打量某幅图,只要大体浏览便可。
先来一点乐子~
为了不使文章过长,请点击此处看图。













